Artificial Intelligence is enjoying one of its (regular) ‘peak of inflated expectations’ from Gartner’s well known hype cycle.

Examples of ‘Mass media hype’ are:
Machine intellectual superiority: “AlphaGo Zero: Google DeepMind supercomputer learns 3,000 years of human knowledge in 40 days”, “AI made this painting”:
artificial intelligence is also driving cars, making money, exploring oceans … and freaking people out.
AI as indispensable everywhere: “Investment in artificial intelligence is essential for our future health”, “Artificial Intelligence Investing Gets Ready For Prime Time”
And on the dark side, the day machines surpass humans is nigh: “ The ‘Father of Artificial Intelligence’ Says Singularity Is 30 Years Away”
Some serious journalist have tried to cut the fog around AI, like the FT’s “AI in banking: the reality behind the hype” and Bloomberg’s “An oral history of AI”.
My goal is to extend the FT’s approach and allow my readers to identify the strengths and weaknesses of AI and be able to discern the hype and potential in my specific professional domain: Finance
What is AI ?
One of the problems with popular media is their inability to differentiate between Artificial General Intelligence (AGI):
intelligence of a machine that could successfully perform any intellectual task that a human being can
and Narrow Artificial Intelligence (NAI or Weak AI):
narrow AI, is artificial intelligence that is focused on one narrow task.
The first question in your mind when you read or hear anything about AI should be: What is the task being solved ?
Notice the words in bold: any task versus one task. Now, when you read the news above you will notice that: AlphaGo is great at playing GO (one task), Self-driving cars only drive (one task), chatbots like Mitsuku can chat like a human (still one task — I just tried to play chess with it and it can’t do it), identify cats in pictures etc. Each example is impressive in its own, but the effort to move from one task to another is still significant.
Once the NAI is setup, it can be replicated almost indefinitely (depending in computer resources) and will not ever tire — that is its power and potential for productivity enhancement.
In a business environment the objective should be on developing NAIs to solve production bottlenecks, or on using them in combination with human discretion (known as Intelligence Augmentation or Amplification):
refers to the effective use of information technology in augmenting human intelligence.
On the other hand, AGI is still far away in the horizon, and quite debatable — I will stay way from it (but if your read reports on the singularity keep in mind they refer to AGI)
How can I develop a NAI?
A particular pet peeve of mine consist of reports in pdf form that contain lots of nice graphs and tables showing great results over an unavailable set of data of a poorly explained algorithm. For that reason I decided to write some examples using Jupyter notebooks (and if you have access to a Google account you can run on their cloud system). The examples should allow access to data (without a password) and should run anywhere with a browser. This ‘research reproducibility’ has some caveats, as it limits computational power and ‘big data’ analysis, but I hope it can show some basics of NAI.
To develop a NAI, you need data. Lots of data.
- Think of the google cat example: datasets like the Open Image Dataset have 9 million annotated images,
- AlphaGo “ learned the best moves over time, simply by playing millions of games against itself.”,
- Vader, a sentiment analyser, used 90,000+ ratings.
Keep that in mind if all your data fits in Excel. The rule of thumb would tell you do not have enough. You also need access to computer power, but this bit has become commoditised — you can rent it from Amazon, Microsoft, Google, etc.
As Yann LeCun and Geoffrey Hinton pointed out:
LECUN: … the [AI] methods required complicated software, lots of data, and powerful computers. …. Between the mid-1990s and mid-2000s, people opted for simpler methods — nobody was really interested in neural nets.
HINTON: … engineers discovered that other methods worked just as well or better on small data sets, so they pursued those avenues …
Finally, pick up a technique (there are lots now, from ‘Deep Learning’ to ‘Random Forests’). I’ll prepare a list later one to help you call the bluffs, and below I show a few techniques that can be used, but for the moment notice that you can divide them in two categories:
Unsupervised learning
As an example of ‘Augmented Intelligence’, I wroteRates Clustering, where I show how using current techniques a system can identify different regime changes in a time series of financial data (I used public term structure of US rates but with some modification you can use other time series)
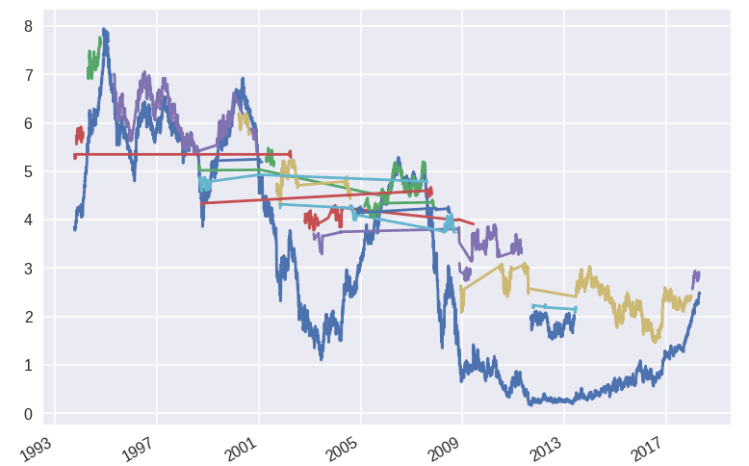
The technique uses a ‘clusterization’ method to identify on its own sections of data that seem to belong to the same ‘cluster’. It is an example of unsupervised learning because all we need is to enter the data and the technique spits out the different clusters. An expert human can then use the output for analysis — she can say that we have entered a new regime in Finance (which needs to be traded in a different form).
Another analog is Google’s cat identifier which clustered images with cats (without having it labeled as a cat) — it was just afterwards that a human labeled the whole cluster as a ‘cat’
Supervised Learning
In unsupervised learning the AI techniques were able to find some structure on its own (in the example above it falls onto the human to identify the meaning). Supervised learning uses all the data and annotated data (e.g., this picture has a cat, this Go game was won by whites) to ‘train’ the AI.
This is where ‘Deep Learning’ comes to mind. The trick to remember is that Deep Learning needs loads of data (millions — as the Google Cat and AlphaGo examples). If you have less you have to use other methods.
One example of supervised learning is my AI as a White Box in Finance:

Here from a publicly available (and anonymized) set of credit card transactions which contain some fraudulent ones, a decision tree was generated from the data. This particular example suits very well the Supervised Learning category, as there is a very strong incentive and requirement to check whether a transaction is valid or not.
A lot of work is done by researchers to pose a problem as a Supervised Learning method — like the AlphaGo example — where millions of game simulations are generated, but also a lot more is done to ‘crowdsource’ the tagging of millions of examples: ImageNet
Even after finding Mechanical Turk, the dataset took two and a half years to complete.
It is not only having access to millions of datapoints, but being able to annotate efficiently the data.
A second example of supervised learning is Sentiment Analysis. If you click on the link you will the basics and a list of application in Finance. As I wrote above, an off-the-shelf sentiment analyser (Vader) required more than 90,000 examples to be manually tagged by Amazon Turk workers .
The holy grail (in the unattainable sense) of Supervised Learning in Finance is the profitable prediction of time series for trading. Notice the ‘predictive texting’ installed in your smartphone: a series of written words is used to suggest the following one. The equivalent in Finance would take the history of prices and other factors coupled with the ‘annotated’ correct prediction. I am preparing a (toy) example — I will keep you posted (but a slight spoiler — a proper forecasting deep learning machine will likely require millions of datapoints and work for a short period of time until ‘the regime changes’).Data Driven Investor
from confusion to clarity not insanity
Follow